Interpolation d'images





Le problème : on a des images $x$ et $y$ et on aimerait trouver "les images entre $x$ et $y$". Une approche beaucoup trop naïve est d'interpoler linéairement les pixels, ce qui donne évidement de très mauvais résultats. Un peu mieux, on peut passer par un neural net en forme d'auto-encoder, puis ensuite interpoler dans l'espace latant obtenu. En effet, on peut espérer que la représentation intermédiaire capture une bonne paramétrisation des input, et qu'il suffit alors de mixer là dedans.
Super, sauf... qu'en fait on a toujours un peu le même problème fondamental qu'avant : on se rend compte que l'interpolation linéaire des pixels nous produit des images peu plausibles (cf deux fantômes superposés sur la figure suivante), ce qui signifie quelque part qu'on est sorti du manifold (immense) des images plausible de l'espace de toutes les images possibles.
Les auteurs de Autoencoder Image Interpolation by Shaping the Latent Space défendent qu'il est utile de poser de bonnes contraintes à l'espace latant obtenu par l'auto-encodage afin de se permettre des interpolations linéaires dedans.
Voici une illustration pour se donner une intuition :
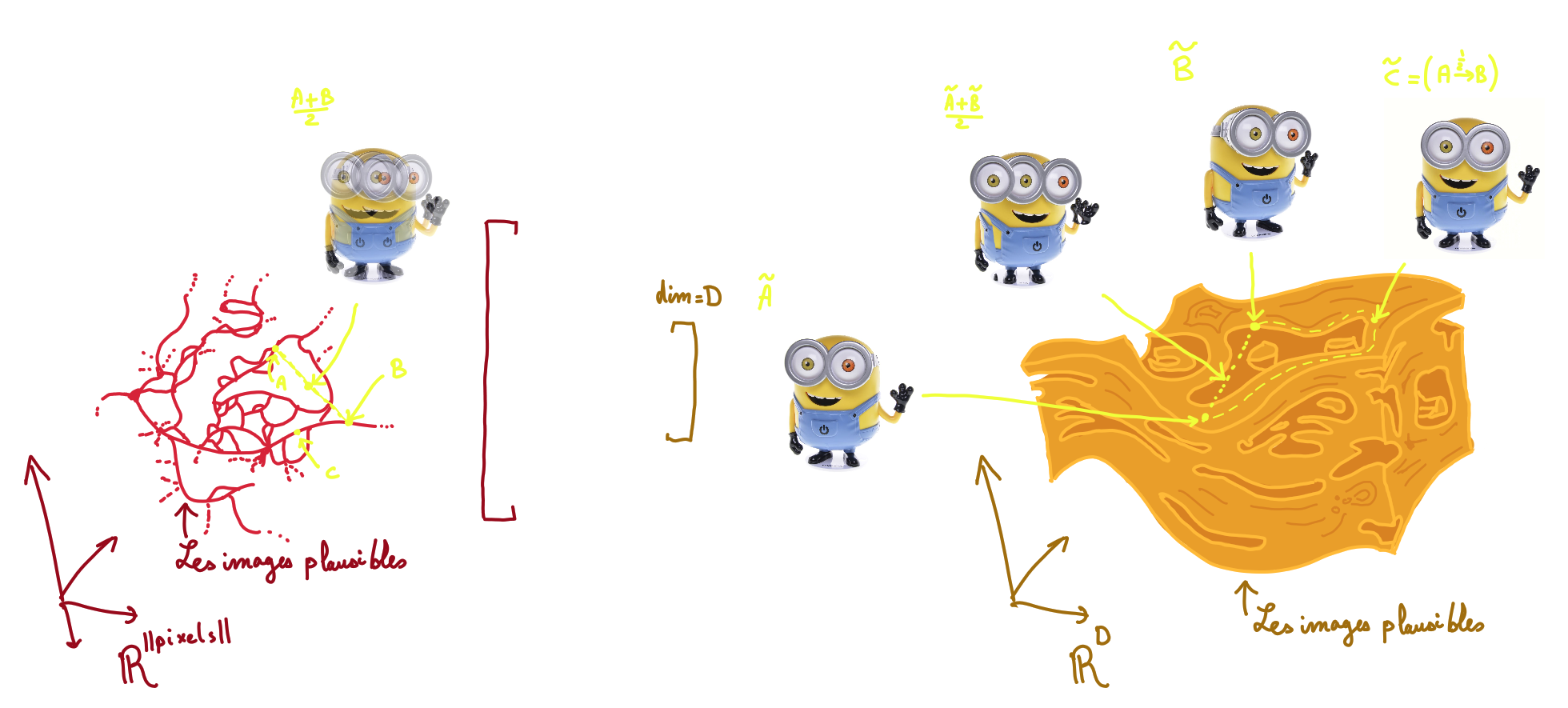
À gauche, on voit l'ensemble des images plausibles dans l'espace de toutes les images possible. Ça a certainement une structure très complexe. Si on prend un image complètement au hasard, quasi certainement, on aura que du bruit : la large majorité des images ne sont pas plausibles. Et du fait de l'existance des vidéos/compression vidéo, on sait que les images ont d'autres images plausibles dans le voisinage (où voisinage est à définir selon le contexte). L'intuition étant qu'à partir de chaque image, on peut changer les pixels progressivement vers d'autres images proches, mais si on prend "n'importe quel changement" (ie combinaison linéaire avec une image de pixels pris au hasard), la plus part du temps on part sur du bruit, et donc une image peu plausible. On peut imaginer qu'en chaque image, on a un tube de tolérance sur le bruit, puis un grand nombre de filaments qui relie notre image vers les autres images voisines. (À noter que ceci est une intuition sans aucun formalisme).
On voit dans l'illustration avec cette intuition que l'ensemble plausible parmis toutes les images étant très creuse, et se ballade dans un nuage autours d'un manifold de dimension plus petite certainement. En fait avec l'auto-encoder et la réduction de composante, on espère tomber sur une paramétrisation pratique de ce manifold, pour que partout on ait des images plausibles, et qu'on y trouve une structure qui relie les images les unes des autres. Seulement, comme sur l'illustration, on peut imaginer des mapping arbitrairement complexe malgré la réductionde dimension. Peut être que cet espace a des trous (régions d'images non plausibles), peut être que le plus court chemin entre une image et une autre est en vérité un très long parcours.
Un exemple concret pour illustrer le propos : supposons qu'on a un point $(x(t),y(t)) = (cos(t),sin(t))$ qui dessine un cercle au cours du temps. Si on connait les positions à $t_i$ et $t_j$, si on fait une interpolation linéaire entre ces points, notre interpolation sera assez mauvaise car on sort complètement de l'espace des positions plausibles. Alors que si on était en coordonnées polaires, une interpolation linéaire sur l'angle aurait été raisonnable : on a besoin d'une bonne représentation, et une bonne façon de relier les points dans cette représentation.
Soit $x_{i→j}(t)$ l'interpolation allant de $x_i$ à $x_j$. On veut :
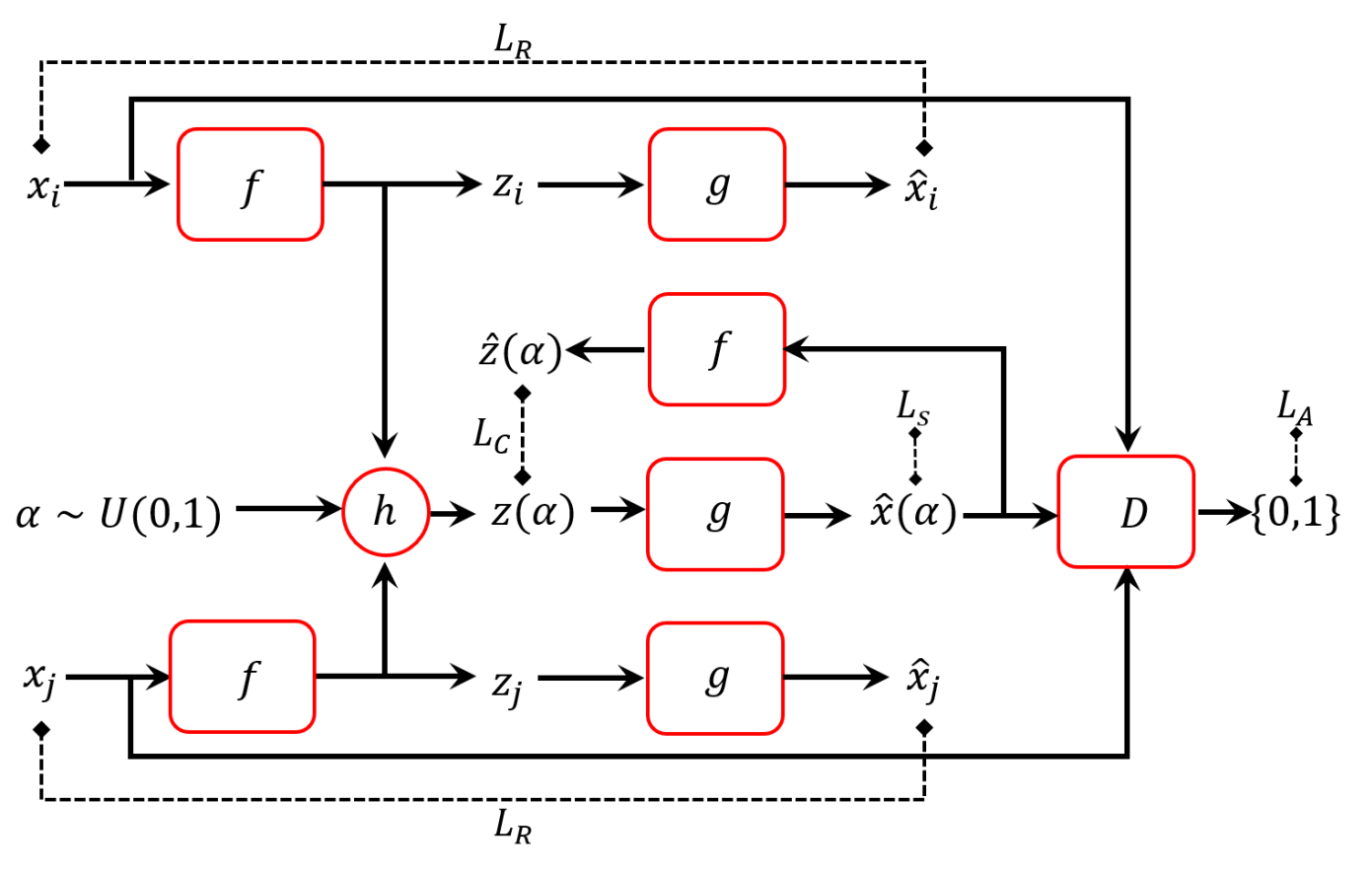
Soit un auto-encodeur $\cases{ φ(x)=z &\texttt{l'encodeur} \\ ψ(z)=\hat{x} &\texttt{le décodeur} }$ et on se permettra de noter $\cases{ z_i=φ(x_i) \\ \hat{x}_i = ψ(φ(x_i)) }$
La stratégie est adverserielle : introduisons un discriminateur $D(x)$ qui apprend à distinguer les images originales des fakes générées, ie $\cases{D(x)&≈1 \\D(ψ(z))&≈0}$ pour un certain $z$ de l'espace latant.
Mais en plus pour essayer de rendre l'espace latent convexe, on va aussi essayer de confondre $D$ avec des images regénérées à partir d'interpolations linéaires dans l'espace latent $z_{i→j}(α) := (1-α)⋅z_i+α⋅z_j$. C'est à dire qu'on veut que $\hat{x}_{i→j}(α):=ψ(z_{i→j}(α))$ deviennent indistinguable d'images réelles, ce qui veut dire que ces images sont plausibles.
En plus, on demande à ce que $\hat{z}_{i→j}(α):=φ(ψ(z_{i→j}(α)))$ soit similaire à $z_{i→j}(α)$, (le plus bijectif possible)
Finalement, on demande à ce que les interpolations linéaire dans l'espace latent soient lisses dans l'espace des images. (cf le point 3. de la section précédente)
Formalisons. Pour une paire d'images $x_i,x_j$ $$ \cases{ \Loss^{i→j} = \Loss^{i→j}_R + λ_A \Loss^{i→j}_A + λ_C \Loss^{i→j}_C + λ_S \Loss^{i→j}_S \\ \Loss^{i→j}_R := \Loss(x_i,\hat{x}_i) + \Loss(x_j,\hat{x}_j) & \texttt{la partie standard de l'auto-encodeur} \\ \Loss^{i→j}_A := ∑_{n=0}^M -\log(D(\hat{x}_{i→j}(n/M))) & \texttt{les images interpolées sont plausibles}\\ \Loss^{i→j}_C := ∑_{n=0}^M |z_{i→j}(n/M)-\hat{z}_{i→j}(n/M)|² & \texttt{bijection de l'autoencodeur}\\ \Loss^{i→j}_S := ∑_{n=0}^M |\frac{∂\hat{x}_{i→j}(n/M)}{∂α}|² & \texttt{le moins rugueux possible (smoothness)} \\ }$$
Intuition de pourquoi c'est une bonne idée : voici un petit schéma interactif qui visualise l'effet de chaque contrainte.
refresh rate
À noter que l'illustration n'est pas basée sur des données réeles, c'est juste pour l'intuition.
Maintenant qu'on sent que ces contraintes permettent de rendre l'espace latent sympathique, implémentons avec pytorch.
Le paper à l'origine de l'idée suggère d'appliquer ceci sur de petits datasets, une peu de la même façon qu'une interpolation bilinéaire qui prend en input que peu d'information (quelques samples, moins de $20$). L'esprit est vraiment de formuler une sorte d'interpolation, mais en plus puissant (et computationellement très cher)
On peut utiliser par exemple des vues 360° d'objets divers comme on trouverait avec le dataset coil-100 ou divers scans comme on en trouve sur 3doid. Cependant il faut se rendre compte d'un problème topologique : on ne peut pas mapper une sphère à un plan sans la déchirer. Donc si on prend le dataset entier, si on ne fait pas attention, l'espace latent ne pourra pas être cohérent avec les contraintes données. La solution est de faire de petites cartes locales et de les sticher ensemble éventuellement. C'est pourquoi nous sélectionnons volontairement des ranges pas trop larges d'angles dans ces datatsets.
Il sera reproduit ici le neural net tel que décrit dans le paper, malgré certaines zones d'ombre. $f$ est conçue "similairement à VGG" comme une suite de convolutions progressant de $16$ channels à $128$, et un maxpool entre chaque convolution. En utilisant la même convension que VGG, nous alternerons entre des phase de convolution et des phrase de réduction.
La paire $f$ et $g$ est assumée symétrique : donc à chaque convolution dans $f$, il y aura une convolution transposée dans $g$, et à chaque maxpool de $f$, il y aura un upscale dans $g$ comme "opération symétrique". L'upscale peut se faire avec nearest neighbour ou quelque chose qui mixe les voisins (comme Bilinear), l'intuition tend à faire croire que nearest neighbour ressemble plus à l'opération inverse de maxpool, mais Bilinear a doné des images plus propres.
Mon intuition personelle tendrait à ne pas faire un neural net complètement symétrique, mais quelque chose de plus simple pour l'encodage, et quelque chose de plus profond pour le décodage, mais nous resterons sur les suggestions du document.
Malheureusement une phrase pour le moins ambigüe décrit "We use max-pooling after each convolutional block and batch normalization with ReLU activations after each learned layer". Sur les multiples interprétations possibles, utiliser que des max pools en guise de non-linéarité semblant un choix surprenant, nous ferons l'assomption que les convolution utilisent max-pooling là où les blocs linéaires utilisent un batch normalization.
Le paper ne précise pas quelle profondeur a été utilisée pour les neural nets. Pour obtenir des images de bonne qualités, un grand nombre de tentatives et tweaking ont été fait jusqu'à obtension d'images auto-encodée visuellement acceptables.
Nous optons ici pour ce modèle : $$\cases{ \texttt{conv\_ch} = [3,16,16,16,32,32,64,64,128,128] \\ \texttt{full\_connected\_layers} = [\texttt{dim\_out},512,500,400,300,256] }$$
où $\texttt{dim\_out}$ est la taille automatiquement calculée après le passage d'un input de shape $(3⨯128⨯128)$ dans la pass de [convolution+maxpool] définie par $\texttt{conv\_ch}$


Pendant l'implémentation, une fausse bonne idée a complètement détruit la qualité du modèle.
L'idée était d'incorporer des informations statistiques basiques utiles au neural net : normalisons la distribution de chaque pixel. $$ (R,G,B) → (R_N,G_N,B_N)=\left(\frac{R-μ_R}{σ_R^2},\frac{G-μ_G}{σ_G^2},\frac{B-μ_B}{σ_B^2}\right)$$ Et bien entendu, au moment d'évaluer la loss, remultiplions par la variance pour n'accorder d'importance que là où il y en a (ne pas amplifier le bruit quoi). $$ \aligned{ loss((RGB_N^1),(RGB_N^2)) &= MSE_N((RGB_N^1),(RGB_N^2))\\ &= MSE((RGB_N^1)⋅σ+μ),((RGB_N^2)⋅σ+μ)\\ &= (σ^2⋅(RGB_N^1-RGB_N^2))^2 }$$

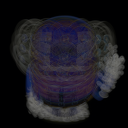
Cette information permet d'obtenir de meilleurs résultats plus rapidement... sauf que c'est accidentellement du overfitting de bas étage.
En effet, à voir l'image moyenne, on voit par exemple sur le bras du personnage, non pas un continuum, mais plusieurs bras superposés. En normalisant par pixels, on va demander au modèle que dans le trou entre les deux positions de bras respecte une distribution très sérée autours du blanc. Donc il sera peu tolérant au concept de translations.
Le résultat de l'image précédente a été réalisé sur ce modèle. Et ça explique en effet sur le petit réseau la présence de la main noir en transparence sur le fond blanc sur quelques images : la construction impose qu'en moyenne, ces pixels soient spécifiquement des mains, et il faut une grande déviation pour réctifier quand c'est nécessaire.
J'insiste encore sur le fait qu'une telle approche entraine non pas à générer de bonnes données, mais à générer les déviations autours de la moyenne du dataset. Dans notre cas de figure, c'est comme si on veut regénérer des surfaces lisses avec de fonctions simples mais dessus une surface rugueuse générée par le mix de plein d'images. On se retrouve avec la tâche supplémentaire d'enlever l'image de base avant de rajouter ce qu'on veut rajouter en somme.
La suite est donc ré-exécutée promptement à la dernière minute, en utilisant la variance et moyenne sur tout le dataset et non par pixel.
Le paper précise qu'on prend pour loss pour le générateur comme $$\Loss_A(\hat{x}) := ∑_{k} -\log(D(\hat{x}_k))$$ mais ne dit pas ce qui a été pris pour le discriminateur, Alors prenons avec un paquet d'images truth $T=\{T_1,...\}$ du dataset et fake $F=\{F_1,...\}$ générées, le loss : $$\Loss_{discr} = ∑_{k} -\log(D(T_k)) + ∑_{k} -\log(1-D(F_k))$$
Le training a été fait avec un ensemble de $5⨯3$ images,
et de la data augmentation par
- ajout de bruit gaussien $σ^2=0.03$
- des translations (sans rotation) avec $\texttt{RandomAffine(translate=(0.02, 0.01), BILINEAR)}$
Voici dans un premier temps juste le résultat d'un bête auto-encodeur.
C'est ici que je choisi l'optimizer pour l'entièreté du projet. Expérimentalement avec les learning rates testés, Adam a montré une convergence plus rapide, moins de ringing et des bors plus propres sur les images obtenues. Les deux seconds points sont probablement atteignable en trainant plus longtemps avec SGD. Le momentum du SGD a aussi été testé sur plusieurs valeurs, mais Adam reste vainqueur.




La fonction de loss diminue, mais oscille aussi. On peut voir dans les images suivantes qu'effectivement, les images s'améliorent pendant un moment, puis se mettent à vibrer autours d'une solution acceptable.
Regardons les interpolations obtenue des espaces latant. Nous allons reconstituer ce même graphique, uniquement à partir
des images aux 4 coins. Remarquez que :
- les coins sont instables car regénéré à partir de leur image dans l'espace latent.
En effet la paire $\{φ,ψ\}$ ne garantissant pas la bijectivité, on a pas tout à fait $x ≈ ψ(φ(x))$.
- le mode collapse est visible : on saut d'un régime à un autre, on sent la nécessité de smoothness
- et finalement on sent que la smoothness doit être contrainte pour que les images intermédiaires soient
convainquantes : utilisé de l'adversarial)
Regardons aussi l'espace latent. Pour regarder des points dans $ℝ^{256}$, nous réduisons avec une PCA. Si le manifold est plat alors par la nature de ce qu'est une PCA, on sait qu'il est plat dans $ℝ^{256}$.
La grille est générée à partir de notre dataset qui contient des variations sur 2 angles. La coloration correpond à une paramétrisation $(θ,φ)→\texttt{RGB}=(θ,φ,0)$
On voit que l'espace latent est libre d'occuper les diverses dimensions de l'espace latent qui lui est mis à disposition. La structure de la grille reste assez propre (sur la figure à droite), ce qui est prometteur. Les remarques faites dans l'introduction sont bien mis en évidence : tirer des lignes droites nous fait sortir du manifold défini par nos images. Il faudrait soit que le manifold devienne plat, soit que l'ensemble convexe défini par nos points représentent des images plausibles.
Cocher les cases suivantes pour activer une contrainte et voir comment le neural net se comporte.
Sans data augmentation, la stratégie ne semble pas fonctionner. Le dataset étant très petit et peu diversifié, le discriminateur identifie des patterns trop spécifique et peu relevant, forcant le générateur à s'aligner sur des features absurdes. Il y a alors comme une résonnace qui amplifie tellement, que le discriminateur devient complètement sûr de lui, fait exploser le log, et la backpropagation énorme détruit le réseau. C'est un peu comme une grosse explosion.
Pour éviter cela on pourrait
- augmenter les données avec du bruit et des transformations [implémenté]
- limiter l'output du log en rajoutant un $ε$ afin de ne jamais dépasser les $\log(ε)$ [implémenté]
- arrêter de train le discriminateur tant que le générateur ne parvient pas à bien mentir, ie éviter
la situation où le discriminateur s'enfonce dans un détail inutile, et entraîne le générateur à se focaliser
avec lui sur un détail inutile devenu important par ces circonstances.
Voici quelques figures du comportement du neural net sans data augmentation.

Le dataset utilisé est accessible ici
Le code est à nettoyer et contient encore quelques variables globales. Des tweaks pourraient être nécessaire en passant à d'autres datasets.
Train/Test split n'a malheureusement pas été effectué pour examiner la qualité des images reconstituées. Une telle analyse serait facile à constituer.
Il reste encore du fine tuning à faire pour reproduire des images de qualité similaire au paper. Malgré les divergence (ou convergence vers un état non désirable), on peut constater que l'évolution du modèle pendant le training montre des phases intéressantes.
Il faudrait tweaker la quantité de déformation pour que les images générées ne tolèrent pas de déformations trop intances. Sur le long terme on pourrait s'attendre à ce que ces déformations disparaissent avec les itérations, mais il est sans doute possible d'aider à la progression en ajustant la quantité de déformations pendant le training.
On pourrait rajouter d'autres déformations plausibles. strech, découpe etc..
Visualiser ce qui se passe si on répère encodage et décodage, avec interpolations entre.
On peut prendre en considération des question de perception humaine dans les images : en passant les images en YUV par exemple, on extrait à moindre coût des informations très utile pour le traitement de notre signal. En effet, on peut être plus stricte sur $Y$ et tolérer plus d'erreur sur $UV$. Et ce sans même transformer explicitement les données : on peut faire la transformation dans le calcul d'erreur uniquement. Ainsi le neural net pourra créer les transformation qu'il désire sans passer explicitement en YUV, mais uniquement en profitant du mou créé par notre loss function.
D'autre part, passer par une base en wavelets qui comprend déjà la notion d'étirement et translation d'un signal local, on pourrait profiter de ces expression, mais c'est peut être trop sophistiqué et pas assez spécifique.
Similairement, rajouter en input la FFT de l'image. On peut mettre en parallèle deux neural net qui travaillent sur des espaces différents, puis ensuite on peut mélanger les deux signaux, exactement comme un U-net, mais sur une base imposée.
Une erreur d'implémentation sur l'aversarial network me donne une idée.
Plutôt que d'entraîner seulement le discriminateur sur les erreurs du neural net, on pourrait rajouter nous même des images volontairement trop distordues. Ainsi le discriminateur peut apprendre à distinguer des erreurs, et le générateur peut apprendre à éviter ces erreurs en regardant le gradient, sans même avoir causé le problème soi même.
On pourrait imaginer un neural net qui génère des distorsions, dont le but est de trouver les distorsions qui accélèrent l'apprentissage du générateur. C'est à dire chercher les bons contrexemples plutôt que les bons exemples.
Une autre façon de voir les chose est une "automatisatoin la data augmentation".